
With the advent of AI applications and ML models, businesses across sectors such as security, finance, healthcare, medicine, and retail are transforming the way they operate and deliver services. However, successful AI-based model implementation depends on the quality of the data. So, if the data is not qualitatively rich, the result may be inaccurate or irrelevant and cause poor performance and failure. This dependency of AI in data engineering shifts the role of data engineering from a supporting role to a critical strategic function. Data engineers not only build the systems that transform raw data into valuable assets; they also do more. They construct the pipelines, architectures, and processes, focusing on core processes like the ETL pipeline and ELT, and leveraging tools such as feature stores.
The importance lies not only in the volume of data but also in comprehending the basic components of these tools and techniques to grasp the essence of data engineering in AI. Without this foundational work, the potential of even the most sophisticated AI algorithms cannot be successfully realized. So, in this blog, we will explore how data engineering practices enable AI to work with well-structured, clean, and accessible data. We will also discuss the concepts of ETL pipelines and ELT, explaining how they prepare data for AI models. Furthermore, we’ll discuss the role of feature stores in streamlining data access and enhancing model performance.
What is Data Engineering?
It is the practice of designing and building systems that can create data collection, storage, transformation, and analysis processes for large amounts of raw different kinds of data, such as structured data, semi-structured data, and unstructured data. This helps data science professionals or data engineers extract valuable insights from it and perform their analysis.
Data engineering in AI consists of the preparation, integration, and transformation of raw data from various sources into a consistent and usable format for AI models. By doing so, businesses can get efficient data pipelines with high data quality and accurate insights and predictions. With the proper strategy of AI in data engineering, key members of an organization—from executives, developers, and data scientists to BI analysts—anyone can access the datasets they need at any time in a manner that is reliable, convenient, and secure.
Key Challenges in Adopting Artificial Intelligence for Enterprises
Let us understand how data engineering in AI can elevate AI applications for enterprises, as it helps in resolving several issues with AI implementation and adoption:
- Data silos are when the information is isolated in different departments, systems, or databases without interoperability. This results in incomplete or fragmented data sets, which can lead to biased AI models, inaccurate predictions, and insights.
- If you don’t give AI algorithms high-quality, well-structured data, they will return noisy or incomplete data that will hurt the performance of AI systems or lead to bad training sets. This means that models are more likely to overfit, underfit, or make wrong generalizations. In addition, “the average financial impact of poor data quality on organizations is $9.7 million per year.”
- It is another challenge for organizations to combine data generated from multiple sources—often using different formats, standards, and structures. Therefore, AI models need unified and coherent datasets to perform accurately, or else it will increase data errors or delays.
- With an inefficient data storage and retrieval process, AI systems struggle to deal with large-scale datasets as they fail to access real-time insight. This leads to latency issues, slow data retrieval times, and high operational costs.
Why Data Engineering is the Driving Force of AI
Did you know that preparing data takes up 80% of a data scientist’s time, not building models? The reason is that data engineering services have become a critical aspect of successful and effective AI usage, as they ensure that data is collected, processed, and made accessible in a structured manner. When organizations learned to leverage ETL pipelines and ELT processes, they could efficiently clean, transform, and store vast amounts of data, enabling accurate and reliable analysis. Feature stores further enhance this by centralizing and standardizing machine learning features, promoting consistency and reusability. Data Engineering also offers the following benefits:
- Data engineering creates a unified data view for accurate AI insights.
- It handles high-volume data in real-time using efficient pipelines.
- Data transformation makes raw data suitable for AI models.
- Enhanced data quality improves AI model training and predictions.
- Data engineering supports data-driven decision-making in enterprises.
Therefore, this robust data infrastructure forms the backbone of AI, empowering machine learning models to deliver insightful and actionable results. In essence, data engineering transforms raw data into valuable insights, making AI solutions effective and impactful. So, let us understand the data-processing methodologies of the ETL pipeline, ELT, and features and what role they play when data engineering is applied for artificial intelligence.
What is ELT (extract, load, transform)?
The process of ELT has unstructured data extracted from a source system and loaded onto a target system to be transformed later, as needed. Therefore, ELT provides business intelligence systems with unstructured, extracted data, eliminating the need for data staging. Moreover, a data pipeline performs three distinct operations on the data during the ELT process.
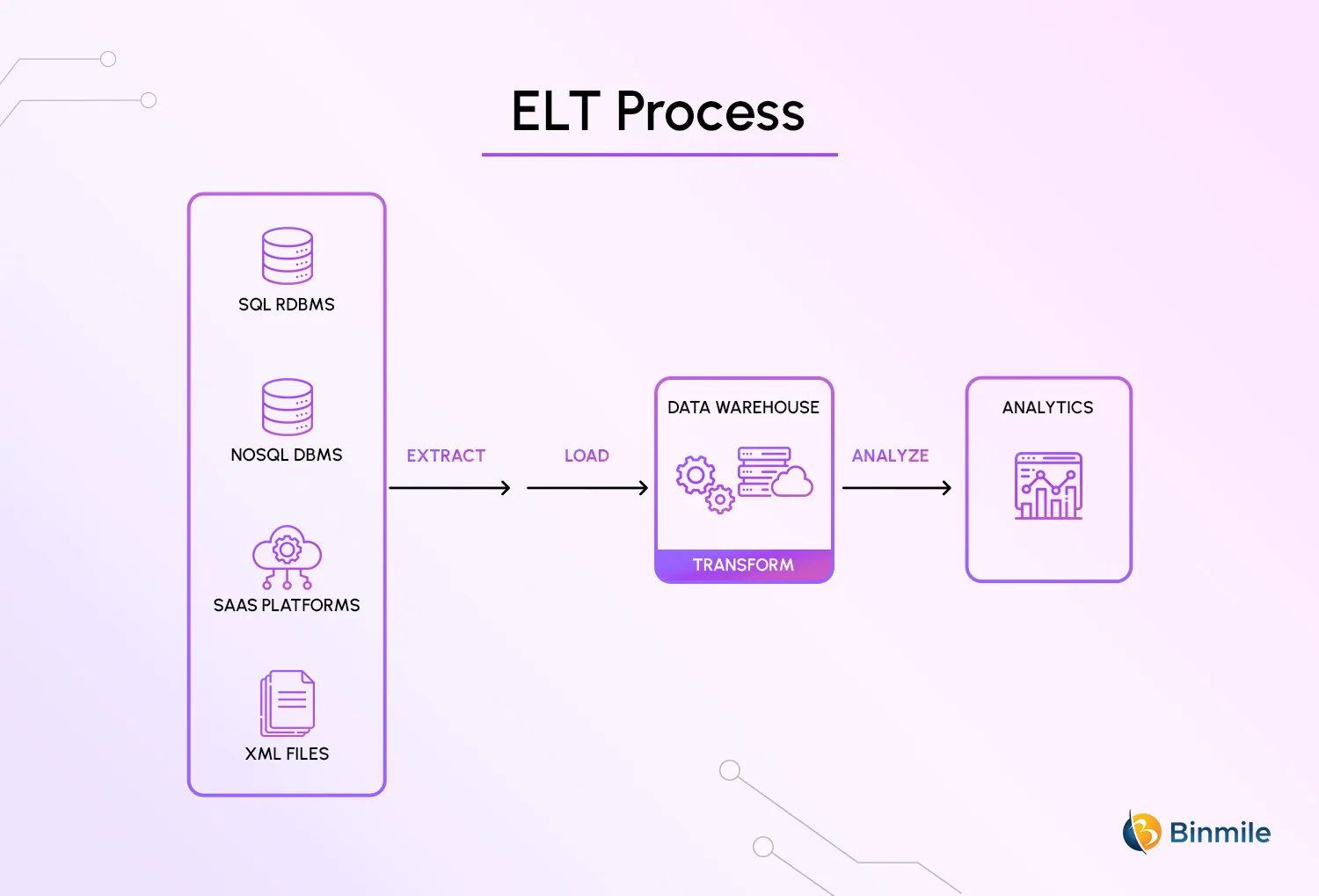
- Extract: To identify and read data from one or more source systems, which may be databases, files, archives, ERP, CRM, or any other viable source of useful data.
- Load: It involves the process of placing the data into the target system. Business intelligence or data analytics tools can analyze the data in a cloud data warehouse.
- Transform: In this process, data is converted from its source format to the format needed for analysis and frequently consists of converting coded data into usable data using code and lookup tables.
For example: replacing codes with values, aggregating numerical sums, and applying mathematical functions.
Key Benefits of ELT
- Leverages the computational power of modern data storage solutions to handle large datasets efficiently.
- It enables real-time data transformations, ensuring up-to-date insights and faster decision-making.
- Allows raw data to be stored first, providing the flexibility to apply transformations as needed for different use cases.
What is ETL (extract, transform, load)?
ETL combines the data from multiple sources into a large, central repository called a ‘data warehouse.’ Extract, transform, and load lets raw datasets be prepared in a format and structure that is more consumable for analytics purposes, resulting in more meaningful insights.
The process of ETL can be best explained through these examples: marketing teams can integrate CRM data with customer feedback on social media to study consumer behavior, or retail companies can improve data management and analyze sales data from various store locations.

Key Benefits of ETL:
- The system ensures clean, consistent, and reliable data through rigorous data cleaning and transformation processes.
- Loads transformed data into structured data warehouses, making it easier to query and analyze.
- The process of ETL facilitates compliance with data governance policies by validating and standardizing data before loading.
Read More: ETL Testing Challenges
ETL vs ELT: What is the Major Difference?
| Factors | ETL | ELT |
|---|---|---|
| Order of the Process | Data is pulled, moved, and transformed on the staging layer, then transferred to the target server | Data is pulled and transferred directly to the target server where transformations are performed. |
| Maintenance | The project requires more maintenance and knowledge. | Virtually maintenance-free as raw data is moved. |
| Processing Time | The data volume increases as a result of transformations. | Less dependent on data volume since raw data is migrated. |
| Infrastructure | The system relies on expensive, difficult-to-scale on-premises environments. | The system utilizes cloud services such as SaaS or PaaS, enabling dynamic scalability without the need for installation. |
| Costs | The project has high initial and running costs. | Low start-up costs, with downstream costs depending on data volume. |
What differentiates ELT vs ETL pipelines is how, when, and where the data transformations are performed. If the process of ETL has the raw data not available in the data warehouse because it is transformed before it is loaded, then with ELT, the raw data is loaded into the data warehouse (data lake), and then transformations occur on the stored data.
What is a Feature Store?
It is an emerging data system used for machine learning models and acts as a centralized hub for storing, processing, and accessing commonly used features. This feature stores and operationalizes the input, tracking, and governance of the data and delivers a measurable piece of data that can be used to teach the model to make predictions about the future based on data from the past.

The feature store also ensures consistency throughout the training and serving of the data, thus not only improving data quality but also reducing redundancy. For example, to predict whether a customer will make a purchase within the next month, variables or features such as the sum of last month’s purchases or the number of website visits this week can be used.
Key Benefits of Feature Stores
- Promotes the reuse of validated features across different models and projects, reducing redundancy.
- The system ensures consistent features between model training and serving, which improves model performance and reliability significantly.
- Enhances collaboration among data scientists by providing a centralized repository for storing and sharing features.
Data Engineering for AI: Key Insights into ETL, ELT, and Feature Store Implementation
Data engineering for AI Using data-processing approaches like ETL and ELT not only ensures data quality and structure but also provides scalability and real-time processing. Feature stores ensure the consistency and reusability of machine learning features. When organizations combine these processes, they can get a robust data infrastructure, empowering accurate and reliable AI models. So, let us understand how you can achieve that:
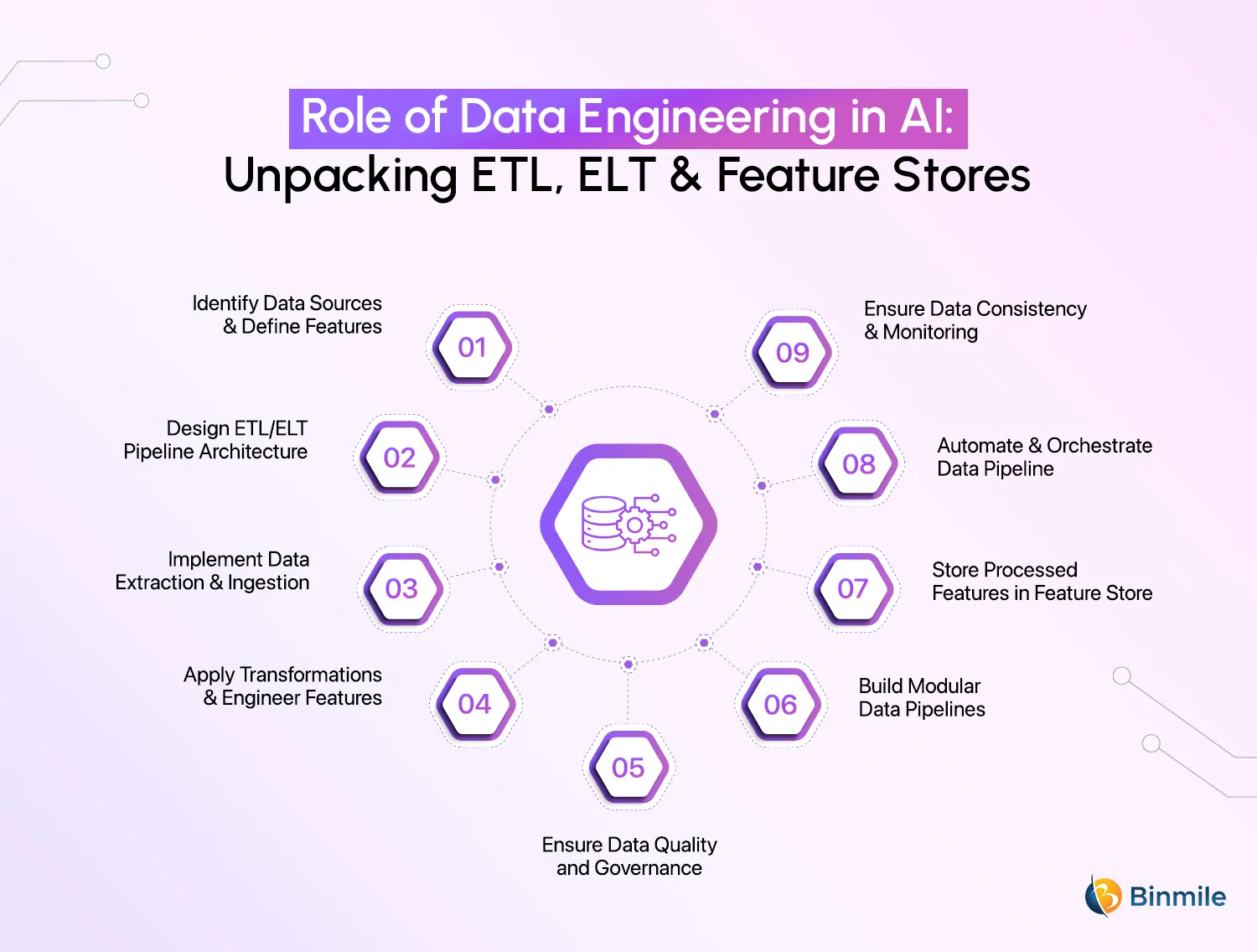
1. Identify Data Sources & Define Features
Before integrating ETL/ELT with a feature store, it is important to identify all the data sources that will be used. These sources can include transactional databases, cloud storage, data lakes, IoT streams, or third-party APIs. Understanding the structure, format, and frequency of data updates is crucial in determining how the data will be extracted. Additionally, defining the features required for machine learning models is a critical step. Features should be carefully selected based on business needs and AI model performance. This process involves working closely with data scientists, engineers, and domain experts to ensure that the right attributes are captured. The features should be well-documented, version-controlled, and aligned with both training and inference use cases for efficient use.
2. Design ETL/ELT Pipeline Architecture
Choosing between ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) depends on factors such as data volume, velocity, and computational resources. ETL is typically used when data transformation happens before loading into storage, making it suitable for structured and batch-processing scenarios. ELT, on the other hand, first loads raw data into a storage system (like a data lake) and then applies transformations, making it more flexible and scalable, especially for large datasets. The pipeline architecture should support batch and streaming data ingestion, fault tolerance, and efficient processing. It should also integrate well with cloud services, distributed computing frameworks, and the feature store, ensuring seamless data movement and storage.
3. Implement Data Extraction & Ingestion
One must identify data sources and ingest them into a centralized repository; this could be a data lake, a data warehouse, or a staging environment where raw data is collected before processing. The extraction process should ensure minimal disruption to source systems and maintain data integrity. Data ingestion can be done in batches (for historical data) or in real-time (for continuously changing data). Tools like Apache Kafka, AWS Glue, Google Cloud Pub/Sub, or Azure Data Factory can be used for efficient ingestion. Also, the right data validation and logging tools should be used to keep track of errors, deal with schema mismatches, and make sure that data from different ingestion pipelines is always the same.
4. Apply Transformations & Engineer Features
Raw data needs to be processed and transformed before it becomes useful for ML models. This step involves cleaning missing values, removing duplicates, normalizing formats, and applying feature engineering techniques. Depending on the use case, transformations may include aggregations, one-hot encoding, binning, scaling, or time-series feature generation. It is important to ensure that these transformations are consistent between training and inference to avoid discrepancies in model performance. Using frameworks such as Apache Spark, Pandas, dbt (data build tool), or SQL-based transformations can help automate and standardize the process. Also, keep in mind that these transformations should be version-controlled and well-documented to maintain reproducibility and facilitate collaboration among teams.
5. Ensure Data Quality and Governance
The reliability of AI models heavily depends on data quality standards operating at a high level. Therefore, establish a comprehensive validation system for detecting discrepancies together with missing values and outliers before data enters your system. The Great Expectations and Deequ tools help with automated data quality checks, which make sure that data meets the requirements for accuracy, stays consistent, and completes data sets correctly. The company must also set up a strong framework for data governance by putting in place role-based access controls (RBAC), metadata documentation systems, and ways to make sure they are following GDPR and HIPAA rules. Setting up such a strong, clean, and verified data set automatically lowers problems later on in model training and deployment. It also makes sure that your AI systems follow the rules and use data in an ethical way.
6. Build Modular Data Pipelines
The design of AI applications demands handling vast amounts of data efficiently, making scalable and modular pipeline design crucial. So, break down data pipelines into independent components for ingestion, transformation, and storage, rather than creating monolithic systems. Moreover, your team of data engineers should employ distributed computing features through Apache Spark or Databricks systems as well as cloud-based elastic storage solutions. This is done to ensure your system handles various workload types with efficiency and accuracy. A properly designed, scalable pipeline guarantees that AI models continuously receive unrestricted access to current, high-quality data.
7. Store Processed Features in Feature Store
A feature store serves as a centralized repository where transformed features are stored, managed, and served to AI models. It enables consistency across training and real-time inference by providing a structured way to retrieve features. The feature store should support batch storage for historical training data and real-time access for online predictions. Popular feature stores such as Feast, Tecton, and Vertex. AI Feature Store allow feature versioning, metadata tracking, and governance, ensuring that data is reliable and traceable. Additionally, integrating the feature store with data lineage tools helps monitor changes in feature definitions, making debugging and troubleshooting easier. Though, the need for proper indexing and caching mechanisms should also be implemented to optimize feature retrieval times, reducing model latency.
8. Automate & Orchestrate Data Pipeline
Workflow orchestration tools like Apache Airflow, Prefect, or Dagster help schedule and manage dependencies across different stages of the pipeline. As automation ensures that features are continuously updated, and new data is processed without manual intervention. This step also involves setting up CI/CD (Continuous Integration/Continuous Deployment) processes to validate and deploy pipeline changes efficiently. Scalable, resilient, and fault-tolerant data operations are made possible by a well-orchestrated pipeline. This makes sure that machine learning models always have access to the newest, best features.
9. Ensure Data Consistency & Monitoring
Maintaining high data quality is critical for AI-driven applications. Any inconsistencies, such as data drift, schema changes, or missing values, can negatively impact model accuracy. Implementing automated data validation tools like Great Expectations or Monte Carlo helps detect anomalies early and ensures that feature transformations remain consistent over time. Another benefit of monitoring ELT or ETL pipelines in real-time allows teams to identify and fix issues before they affect production models. Additionally, setting up alerting systems for unexpected changes in feature distributions or upstream data sources helps maintain stability and improve data governance and reliability.
Your AI models deserve reliable, clean data delivered at the speed of business—get custom data pipelines for your industry with us!

So far we have understood the intricate concept of data engineering and its role in ensuring a successful AI implementation for organizations. We also talked about how ETL and ELT, two major data engineering approaches, along with feature stores, help data engineers build a strong base for AI-driven data engineering by making sure they have high-quality data, scalable infrastructure, and efficient workflows that power AI systems that are reliable and perform well. Let us now explore a few tips to perfect the entirety of data engineering in AI for optimal results and zero errors.
Also Read: What is Zero-Downtime Deployments
Essential Best Practices for Data Engineering in AI: A Comprehensive Guide
Here are the best 5 practices to ensure you are optimizing your AI Solutions for Success:
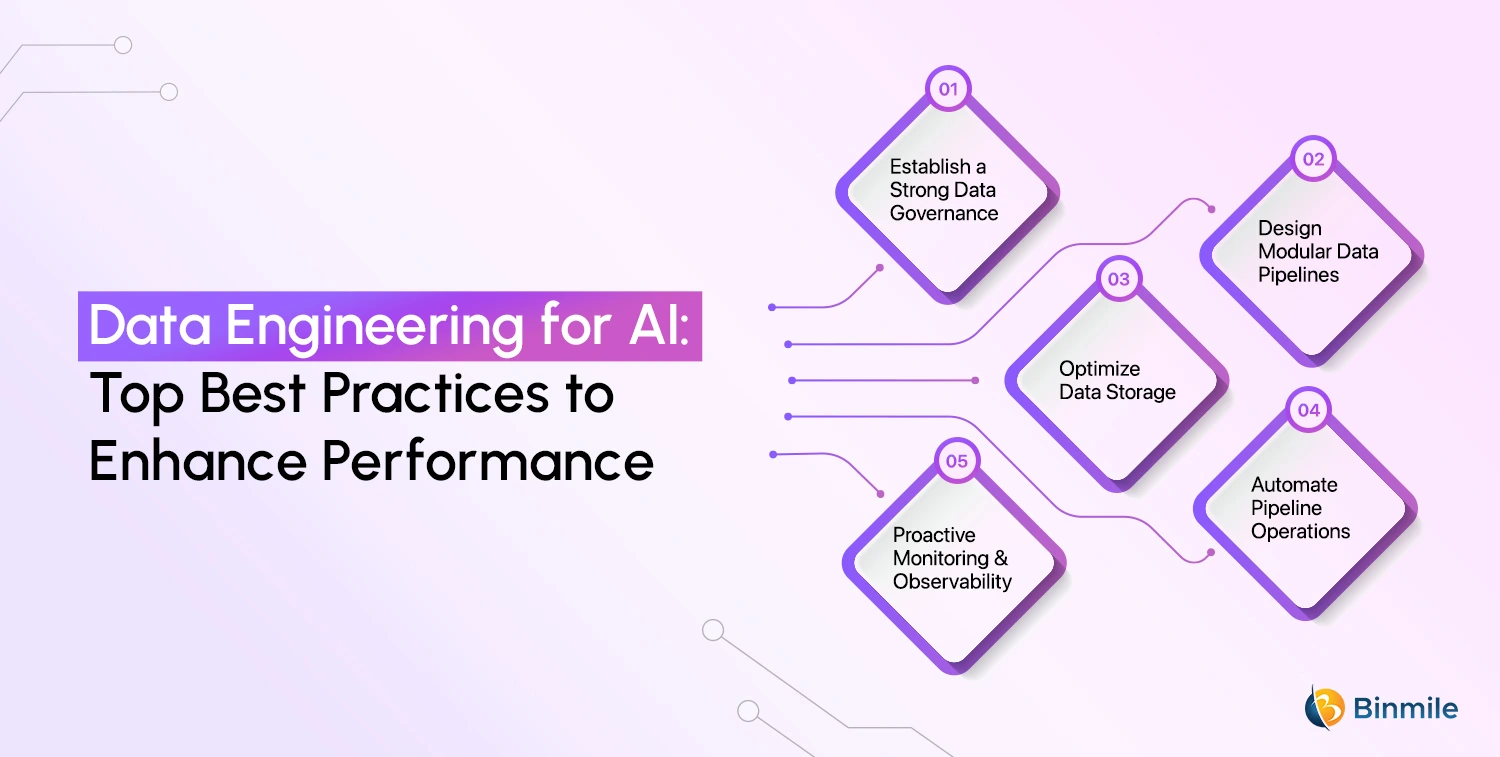
1: Establish a Strong Data Governance
A well-defined data governance framework includes setting policies for data access, security, and compliance while ensuring data integrity and quality. Moreover, as the focus on ethical AI intensifies, it is anticipated that by 2027, 70% of organizations will be looking to set up frameworks for responsible deployment of AI. Therefore, organizations should implement role-based access controls (RBAC) to regulate who can read, write, or modify data. Additionally, maintaining proper metadata documentation helps data scientists and engineers understand data sources, lineage, and transformations. Regulatory compliance, such as GDPR or HIPAA, must also be considered to prevent legal and ethical issues. A strong governance framework ensures that AI models are built on trustworthy, high-quality data, reducing bias and improving overall reliability.
2: Design Modular Data Pipelines
AI applications require handling vast amounts of data efficiently, making scalability a key consideration. Designing modular data pipelines allows teams to build flexible workflows that can be adjusted as business needs evolve. Instead of creating monolithic pipelines, breaking them down into independent, reusable components. These can be data ingestion, transformation, and storage to improve maintainability. Cloud-based solutions, distributed computing frameworks (like Apache Spark or Databricks), and containerization tools (such as Kubernetes and Docker) help scale pipelines dynamically based on workload demands. A well-structured pipeline architecture ensures that AI models receive fresh and accurate data without performance bottlenecks
3: Optimize Data Storage
When AI workload storage systems are being optimized for training and inference tasks, how quickly they can access large datasets is a very important factor. Decision-useful data storage formats that include Parquet, Avro, and ORC provide an optimal environment for efficient data access. You should apply data partitioning along with indexing and caching methods to achieve faster database response times during regular requests. AI applications can access real-time performance through modern data warehouses and feature stores like Snowflake, BigQuery, and Redshift. These stores make high-performance storage easy to access and cost-effective.
4: Automate Pipeline Operations
Data processing dependencies get managed by scheduling and monitoring workflows through tools such as Apache Airflow or Dagster. Thus, AI models benefit from automation as it ensures the models can access reliable and high-quality information without the need for human intervention. CI/CD principles should be applied to data engineering workflows, which enable test automation as well as deployment and rollback procedures for ETL scripts and feature engineering code. This automation-first approach reduces manual intervention, minimizes errors, and enables teams to focus on strategic improvements rather than routine maintenance.
5: Proactive Monitoring and Observability
You must perform continuous monitoring of data pipelines to maintain your AI systems’ reliability and high functionality. So, set up and track key metrics like data freshness, processing latency, and quality scores to detect anomalies early. Your organization can also leverage automated alerts to flag data drift, missing records, or unexpected format changes. This will prevent the impact on model performance. In addition, developing real-time dashboards can also provide real-time visibility into data system health. This ensures teams can quickly diagnose and resolve issues. Remember, these regular audits and assessments of data pipelines help you not only maintain compliance and adaptability to evolving AI needs but also prevent AI systems from making costly errors.
Develop AI solutions with high-quality data, efficient processing, and seamless integration, and ensure long-term reliability and performance for your apps!

Closing Statement
Data engineering for AI encompasses not only the transfer of data from one location to another but also the establishment of a secure, feasible, and profitable foundation for machine learning. Therefore, data engineering services play a crucial role in the success of every AI-driven application. They ensure your ML models receive high-quality and well-processed data. However, remember that your choice of data processing should be well-suited to your specific business requirements. Whether you adopt ETL for its robust transformations, ELT for its flexibility with modern cloud warehouses, or implement feature stores for ML-specific needs, the objective remains the same: to deliver high-quality, reliable data to power your AI projects.
Thereby, as the field of data engineering for AI continues to undergo transformation, businesses must remain focused on generating efficient data processing, scalable infrastructure, and consistent data quality. For organizations, keeping up with these demands requires a solid understanding of key data engineering practices. In this blog, we discussed the core concepts of ETL, ELT, and feature stores and the way they work together to streamline AI workflows. Hopefully, this will give the insight to leverage these tools and methods to design scalable data and build an efficient, scalable, and maintainable AI infrastructure.
Ready to power your AI implementation journey? Contact us today and explore innovative solutions for seamless AI-driven data engineering!









