
Businesses run on data, from enhancing operations efficiency, flexibility, and ability to innovate, to boosting customer engagement; it is transforming the way we work and do business. However, in its raw state, data has no value unless it is gathered effectively, completely, accurately, and connected to other relevant data. To ensure employees or stakeholders have the right data for decision-making, companies often invest in different data management solutions. One of them is the ETL process, which is extract, transform, and load (ETL). It consists of copying data from multiple sources, transforming it into a standardized format, and then loading it into a destination system, often presenting the data in a new context.
As businesses generate and handle massive volumes of information every day, extract, transform, and load acts as the foundation for creating reliable, structured, and accessible datasets that power smarter decisions. This is why understanding ETL in data warehousing is essential for implementing the process to achieve maximum and optimal results in today’s digital economy. Therefore, in this blog, we’ll explain what is the ETL process, how an ETL data warehouse works, and its key components. We’ll also cover the benefits of ETL database, best practices for implementation, and top ETL tools to help you maximize its impact on business intelligence and decision-making.
What is the ETL Process?
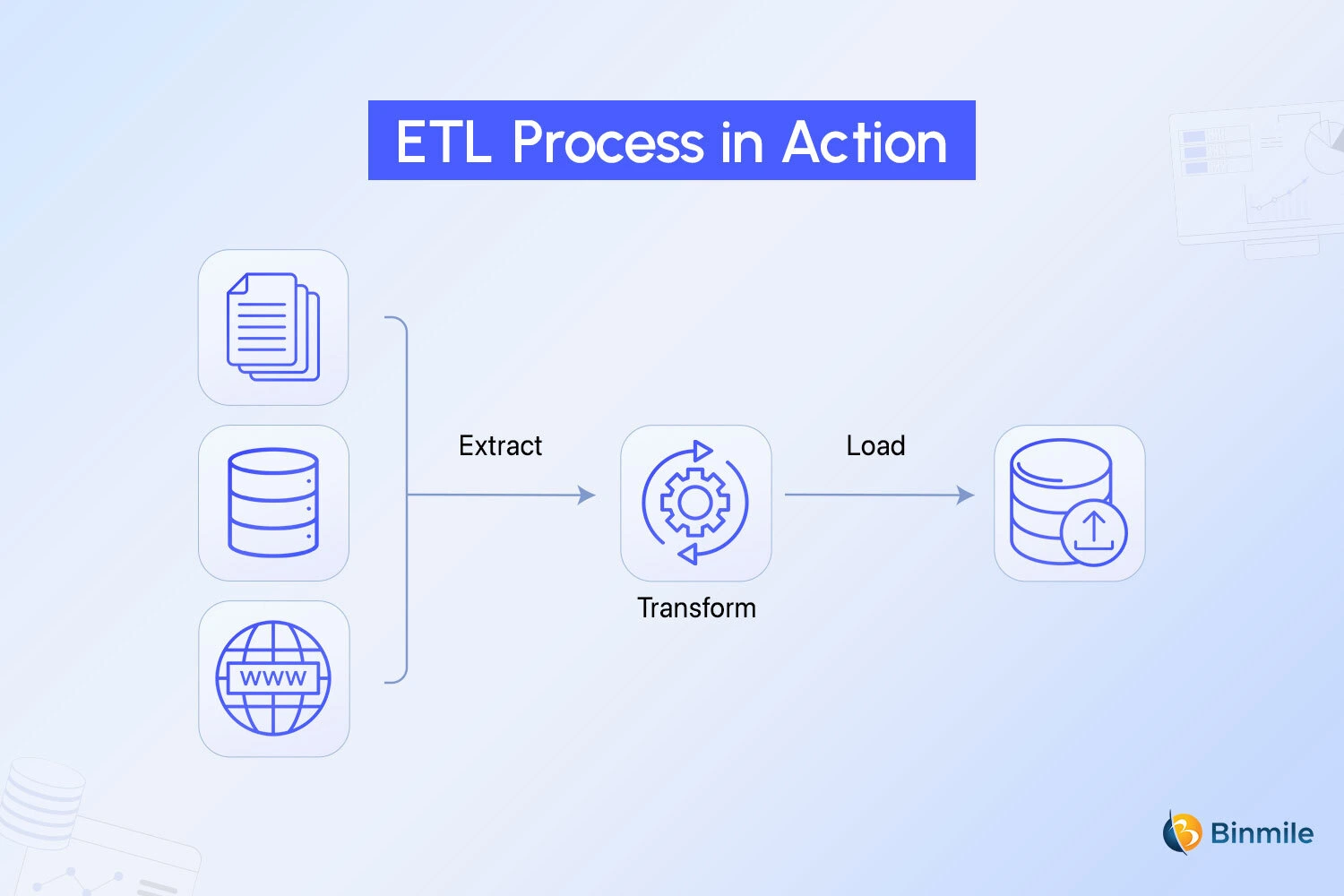
ETL, or Extract, Transform, and Load, is the process of gathering data from various sources and combining them into a large, unified repository, commonly referred to as an ETL data warehouse or data lake. The primary purpose of the ETL process is to bring in data from different sources and transform it so that it conforms to a standard data type or data model.
How ETL Works
The easiest way to understand how the ETL data warehouse works is to understand what happens in each step of the process. Let’s explain this through a detailed overview of the entire process.
Extract
In this step, raw data is copied or exported from source locations to a staging area. Your data analysts or management experts will extract data from a variety of different sources (which can be structured or unstructured). It can be these, but is not limited to:
- Wearables or Smart meters
- Custom CRM and ERP systems
- Push notification logs
- Inventory systems
- Web pages
Transform
Data is processed, then transformed and consolidated, for its intended analytical use case. There are multiple stages to this ETL data warehouse process, such as:
- The process involves filtering, cleansing, aggregating, deduplicating, validating, and authenticating the data.
- Conduct calculations, translations, or summarizations of the raw data. It means your team will change either row or column headers for consistency, converting currencies or other units of measurement, editing text strings, and more.
- Perform audits to ensure the quality, integrity, and compliance of the data used (seek data governance services if you don’t know where to begin.)
- Ensure the data follows industry, data governance, or regulations via encryption or other metrics.
Load
This is the last step and is often automated and performed in a well-defined, continuous, and batch-driven manner. Another aspect while loading is that it’s usually done when traffic on the source systems and the data warehouse is at its lowest for minimal disruptions or zero downtime. It consists of:
- Establishes the foundational dataset in the warehouse.
- Captures ongoing changes via scheduled or event-driven triggers.
- Periodically replaces entire datasets to maintain consistency or correct systemic drift.
- Timed during low system traffic to minimize disruption and optimize performance.
- Validates schema alignment, row counts, and referential consistency after ingestion.
Key Benefits of ETL Process for Businesses
Extract, transform, and load offers a variety of advantages to businesses, other than just improving business intelligence or analytics. So, let’s explore them briefly:
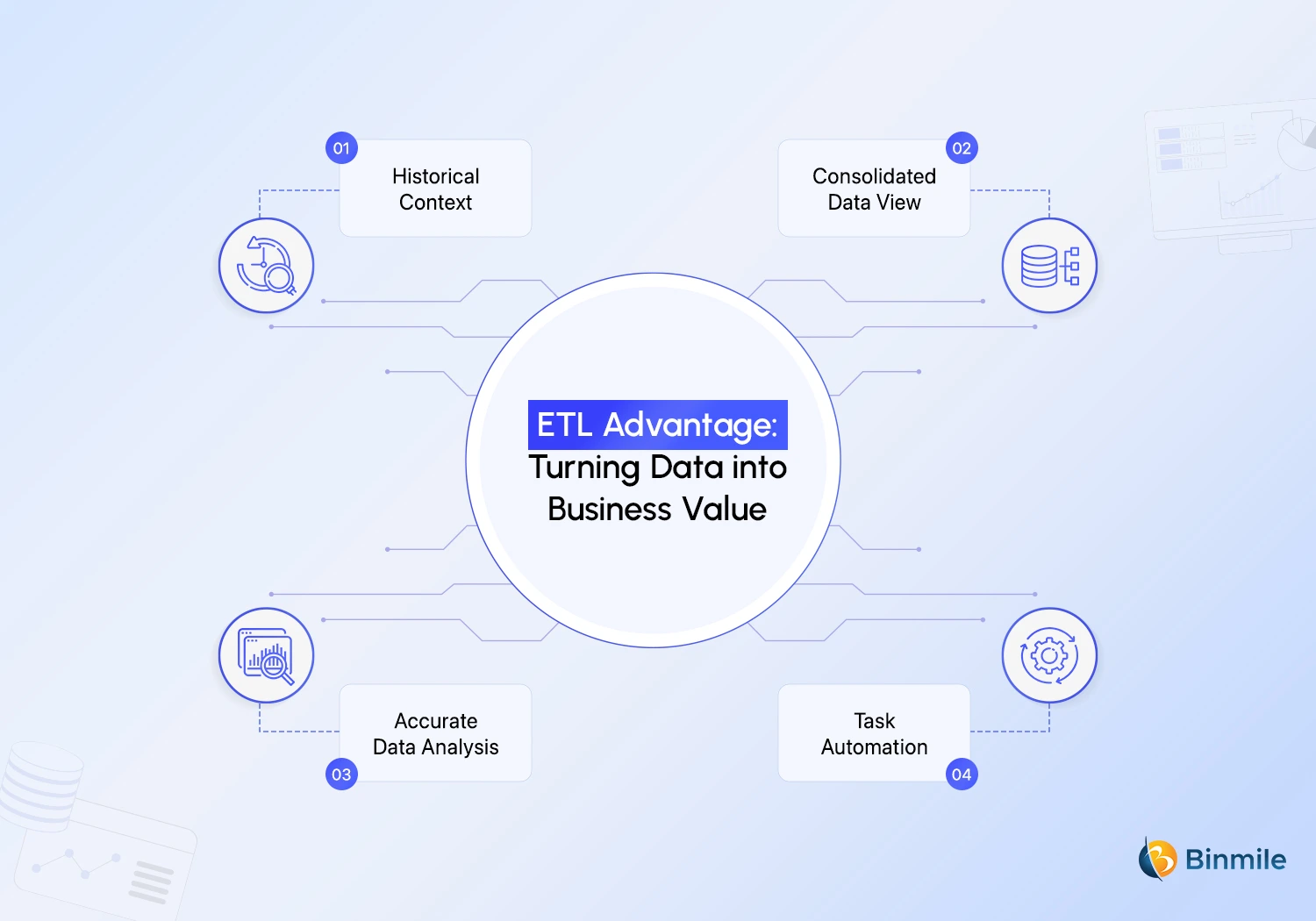
- Historical Context: Organizations get to understand their historical data by combining legacy data with data from new platforms and applications. This helps you view older datasets alongside more recent information, therefore, enabling you to preserve and analyze data over time.
- Consolidated Data View: It’s challenging to manage data from various sources, as multiple datasets require time and coordination, resulting in inefficiencies and delays. But with ETL databases’ capabilities to combine databases and various forms of data into a single, unified view, you can effectively and accurately move, categorize, or standardize data. This makes it easier to analyze, visualize, and make sense of large datasets.
- Accurate Data Analysis: When you have a consolidated overview of your data and know its source, you can understand and meet compliance and regulatory standards with priority. In addition, by integrating ETL database tools with data quality tools to profile, audit, and clean data, you can make sure that the data is trustworthy. Therefore, this foundation of reliable, well-sourced data enables confident decision-making, predictive modeling, and long-term strategic planning.
- Task Automation: Most organizations can automate ETL processes in data warehousing for efficient and faster analysis. Different methods, such as the data migration process, can be set up to integrate data changes periodically or even at runtime, and these processes can be automated on demand. As a result, data engineers can spend more time innovating and less time managing tedious tasks, such as data movement and formatting. Thus, not only accelerates delivery cycles but also strengthens data reliability by reducing manual errors and operational bottlenecks.
Build smarter data pipelines & future-proof your analytics with our expert data engineering services designed for smarter business outcomes.
ETL vs. ELT: Which One Will Future-Proof Your Data Warehouse?
The biggest difference between ETL and ELT lies in where the data transformation takes place. In extract, transform, and load, data is transformed before it is loaded into the data warehouse, using external tools or servers. In ELT, raw data is loaded first and then transformed within the warehouse using its built-in processing capabilities.
| Factors | ETL | ELT |
| Data Flow | Data is transformed first and then loaded into the warehouse. | Data is loaded first and then transformed inside the warehouse |
| Processing Location | Uses a separate ETL server or external tools for transformation. | Uses the data warehouse’s native processing power for transformation. |
| Performance | It can be slower with large or unstructured datasets. | Handles large data volumes faster in modern cloud setups. |
| Use Case | Suited for traditional on-premise systems and structured data. | Ideal for cloud-based warehouses and big data environments. |
| Cost | Requires dedicated ETL infrastructure, increasing costs. | More cost-efficient since processing happens within the warehouse. |
This shift makes the ELT database better suited for modern, cloud-native environments that need real-time, large-scale data processing.
How to Effectively Implement ETL Process for Smarter Business Intelligence: 7 Best Practices
Data management, when done right, keeps your pipelines efficient and your warehouse dependable. Done wrong, it can lead to delays, errors, and wasted resources. To avoid common pitfalls and build a process that scales with your needs, here are seven best data engineering practices for implementing extract, transform, and load effectively.
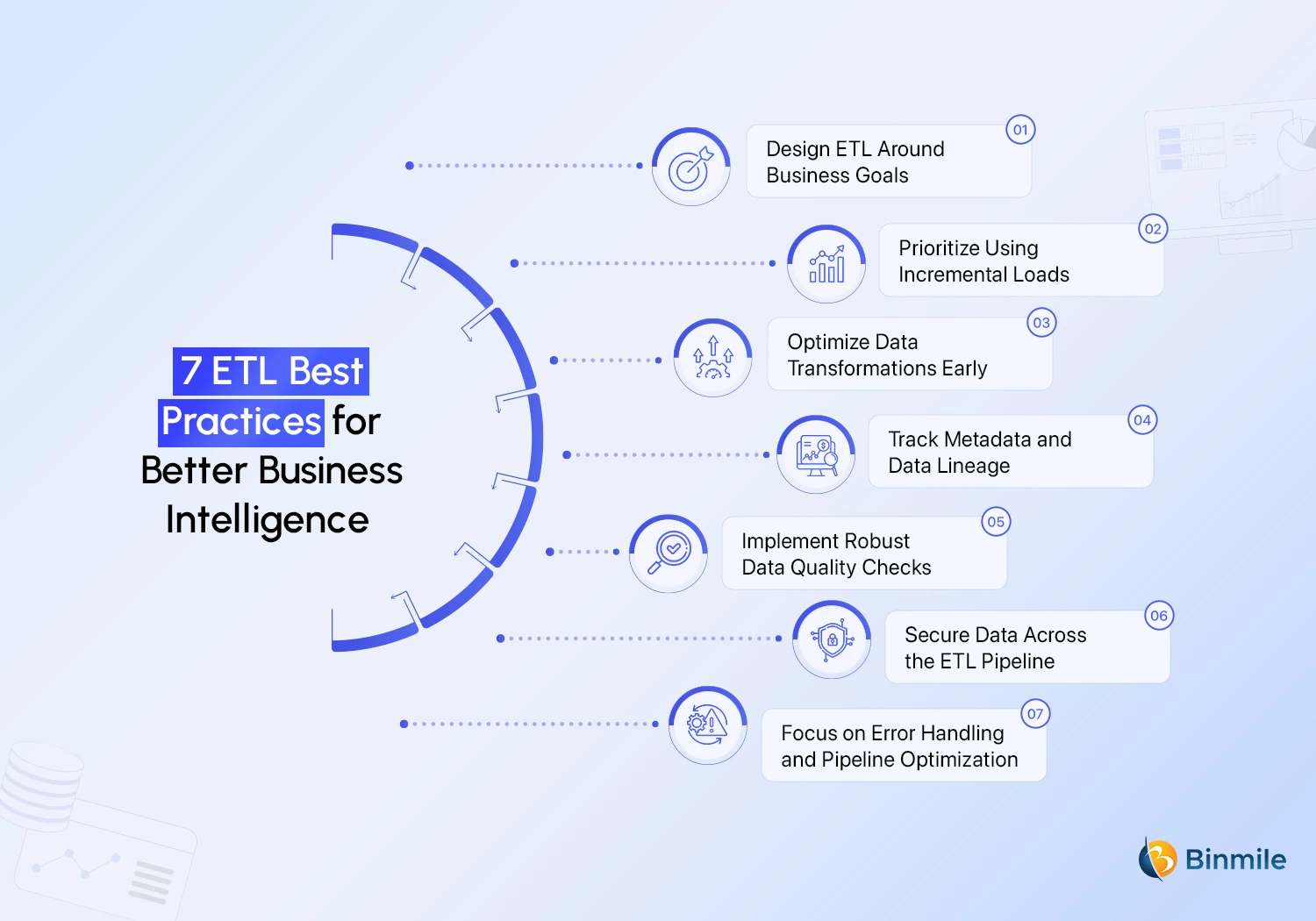
1. Design ETL Around Business Goals
Start with a clear understanding of what the data warehouse is solving. Define KPIs, reporting needs, and target queries before finalizing your ETL database design to ensure a comprehensive and effective solution. You should also involve business stakeholders early to identify critical datasets and transformation rules. Not only do you extract relevant, high-value data, but you also reduce processing time, storage costs, and unnecessary transformations.
A business-driven ETL process also improves pipeline performance and scalability, as it avoids over-engineering and eliminates bottlenecks. By aligning ETL database logic with varied data analytics use cases, you ensure the warehouse delivers meaningful insights rather than becoming a dumping ground for unused data.
2. Prioritize Using Incremental Loads
Avoid reloading entire datasets unless necessary. Instead, configure extract, transform, and load pipelines to capture only new, updated, or deleted records using techniques such as Change Data Capture (CDC) or timestamp-based filters. Incremental loading reduces resource consumption, speeds up processing, and minimizes data latency, ensuring the warehouse remains responsive and efficient.
It also prevents bottlenecks during peak load times and helps maintain historical data consistency by avoiding the need to process the same information repeatedly. Additionally, this approach is especially critical for large-scale systems where complete refreshes can impact performance and extend maintenance windows unnecessarily.
3. Optimize Data Transformations Early
Push transformations as close to the source as possible when dealing with large datasets. Filtering, aggregating, and restructuring data before moving it reduces network load and improves pipeline efficiency. For example, if your analytics team only needs three columns out of twenty, drop the unnecessary columns during extraction rather than after loading.
Similarly, apply business logic, standardization, and data quality rules before staging whenever possible. Early transformations simplify downstream processing, reduce storage requirements, and lower the overall ETL process runtime, helping to keep the warehouse lean and efficient.
4. Track Metadata and Data Lineage
Keep a clear record of where your data originates, how it is processed, and where it is stored. This helps you understand the whole journey of every dataset through your extract, transform, and load pipeline. When a source system updates its schema or a transformation step changes, lineage tracking enables you to identify the impact and resolve issues more quickly.
Many ETL testing challenges stem from poor visibility into metadata and lineage—especially when schema drift, silent transformations, or undocumented dependencies cause downstream failures. Maintaining proper metadata also improves collaboration between teams and builds trust in the reports generated from the warehouse. It’s not about cleaning data, it’s about knowing its history and ensuring transparency.
5. Implement Robust Data Quality Checks
Set up automated validation steps within the ETL database workflow to catch missing, inconsistent, or duplicate records before they reach the warehouse. Use schema enforcement, referential integrity rules, and profiling techniques to ensure clean, reliable datasets. For example, configure alerts for mismatched data types, incomplete fields, or unexpected volume spikes. Maintaining high data quality early prevents inaccurate analytics and reduces manual cleanups later.
This is where data governance vs data management becomes critical: governance defines the policies and standards for data quality, while management executes those rules through monitoring, validation, and remediation. Additionally, continuous tracking helps quickly identify upstream issues in source systems, ensuring that business-critical dashboards and reports are consistently powered by trustworthy and accurate information.
6. Secure Data Across the ETL Pipeline
Data security should be embedded at every extract, transform, and load stage. Use role-based access controls (RBAC) to restrict sensitive data, and encrypt information both in transit and at rest to protect against breaches. Mask personally identifiable information (PII) where not required, and maintain audit trails for regulatory compliance.
For a cloud-based ETL process, ensure your warehouse adheres to industry security standards, such as SOC 2 or ISO 27001. Incorporating these safeguards prevents unauthorized access, ensures adherence to data privacy regulations, and builds trust in your organization’s data handling practices.
7. Focus on Error Handling and Pipeline Optimization
Build an ETL process in data warehousing with automated checkpoints, retry mechanisms, and failure notifications to minimize downtime. Instead of halting entire workflows, isolate failures to specific stages and rerun only the affected segments. For example, if a transformation step fails, the system should flag the issue, skip redundant reprocessing, and continue unaffected through the remaining stages.
Integrate real-time monitoring tools to track pipeline health, trigger alerts, and provide detailed diagnostic logs for enhanced visibility and troubleshooting. Combine this with regular ETL testing with AI/ML and performance reviews to identify bottlenecks and optimize efficiency. A proactive approach ensures higher pipeline uptime, faster recovery, and scalable, reliable data flows.
Optimize data quality, security, and future-proof your data strategy by integrating best-in-class ETL practices with expert data governance solutions.
Best ETL Tools for Data Warehousing: Our Top Picks
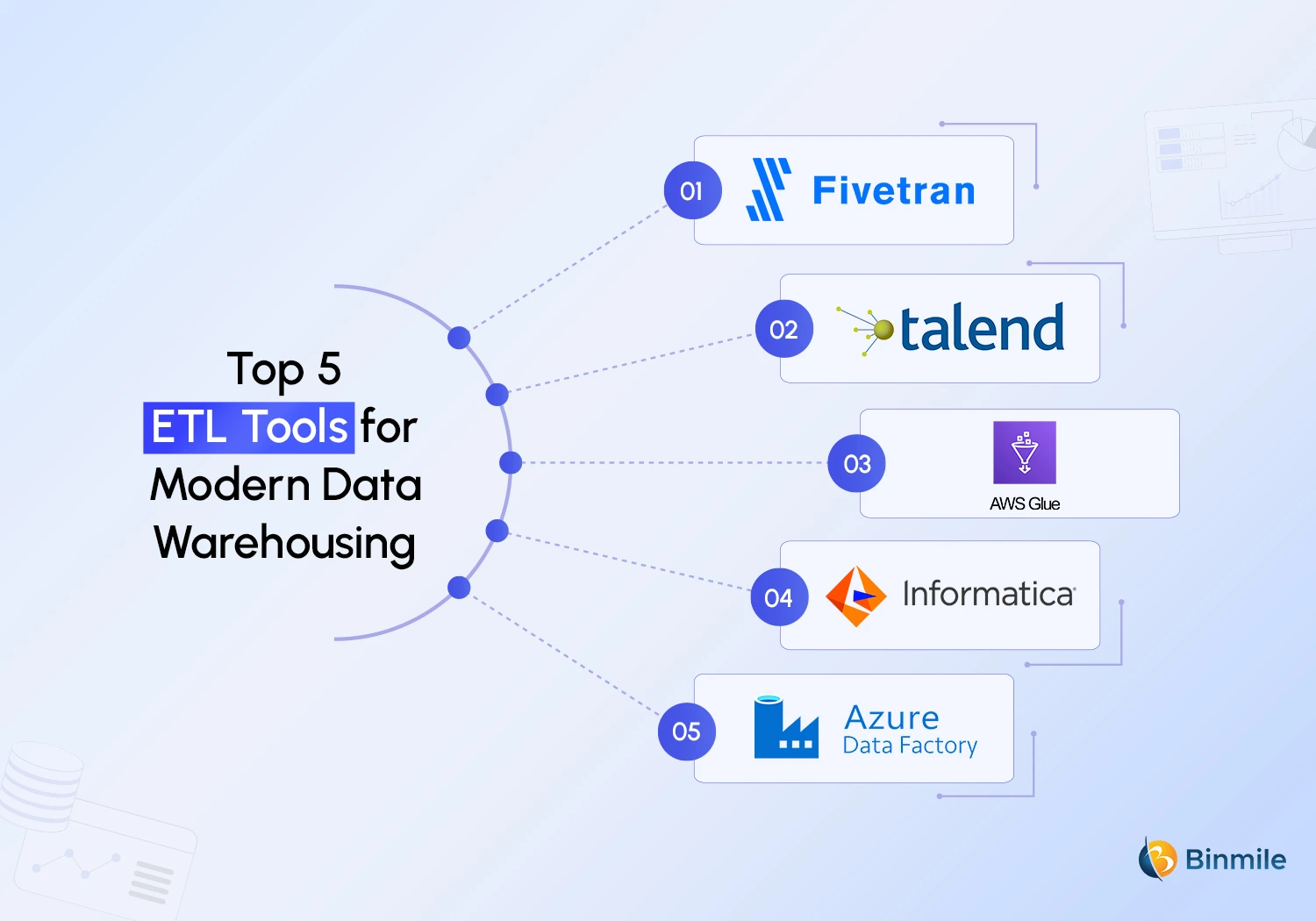
1: Fivetran
Cloud-based ETL tool with automated connectors and near-zero maintenance, popular for enabling fast, real-time analytics. It’s best for real-time analytics pipelines and to sync SaaS app data into Snowflake or BigQuery.
Pricing:
- Subscription-based, starts at $0.01 per credit (pay-per-use)
- Free trial available
- Pricing scales with data volume and connectors used
2: Talend
Open-source ETL platform known for flexible integrations, strong data quality features, and hybrid deployment support. Used to build hybrid extract, transform, and load pipelines that combine on-premises ERP software data with cloud analytics platforms.
Pricing:
- Open-source version available for free
- Talend Cloud: Starts at ~$1,170 per user/year
- Enterprise plans are quote-based
3: AWS Glue
Fully-managed, serverless ETL service within the AWS ecosystem that simplifies the entire process of discovering, preparing, and combining data for application development, ML, and data analytics.
Pricing:
- Pay-as-you-go model
- ~$0.44 per DPU-hour for ETL jobs
- Separate charges for crawlers and data cataloging
4: Informatica PowerCenter
Enterprise ETL solution valued for its scalability, complex transformation handling, and enterprise-grade security. When you want to handle complex data transformations and compliance-driven workflows in large enterprises like banks and healthcare firms.
Pricing:
- Enterprise-focused, custom pricing
- Based on the number of connectors, data volume, and nodes
- Offers subscription and perpetual licensing options
5: Azure Data Factory
Cloud-based ETL tool designed for seamless integration with Azure services. It is ideal for orchestrating complex multi-source ETL pipelines across Azure Synapse, Power BI interactive dashboards, and Databricks.
Pricing:
- Pay-per-use pricing
- ~$1 per 1,000 run activity executions
- Data movement costs vary by region and volume
Closing Statement on ETL Process
The ETL process in data warehousing is more than just moving data; it’s also about making it usable and accessible. By extracting information from various sources, transforming it into a consistent format, and loading it into a centralized warehouse, the extract, transform, and load process ensures that teams work with accurate, reliable, and ready-to-analyze data. Selecting the right ETL approach, tools, and practices is critical to maintaining data quality and supporting scalable reporting. When done well, ETL simplifies workflows, reduces errors, and ensures that decision-makers always have the information they need when they need it.
Hopefully, this blog has given you an in-depth understanding of the ETL process in data warehousing, its benefits, best practices, and top ETL tools, and enabled you to make data management more efficient. A well-structured extract, transform, and load setup helps businesses streamline reporting, improve analytics, and respond to insights faster. If you want to elevate your data strategy, our data engineering experts can help. We offer industry-leading data integration tools and solutions to provide you with the most comprehensive, fully developed, and end-to-end data pipelines, enabling you to maximize the value of your data.
Ready to strengthen your data strategy? Claim your free strategy session today and discover solutions that help you optimize every stage of your ETL process!









