
- benefits of data quality in AI
- best practices of data quality in AI
- data integrity vs data quality
- Data Quality Challenges in AI
- data quality for AI
- data quality in AI
- Data Quality Metrics
- importance of data quality in AI for business
- significance of data quality in AI
- strategy for data quality in AI
- what is data quality
With the world becoming increasingly AI-driven and every aspect of how businesses operate, develop, and deliver being transformed, the role of data becomes critical. Data quality in AI becomes more crucial since poor data quality costs organizations an average of $12.9 million annually. In addition, high data quality drives the success of AI systems. It enhances their ability to generate reliable, accurate outputs and unbiased insights that drive better decision-making and improve customer experiences. Otherwise, organizations risk getting biased, skewed, or irrelevant outputs from AI-powered applications, ultimately undermining their value to organizations.
Therefore, to help you take advantage of the transformative power of data and AI innovations, this blog will discuss data quality and why it is vital for AI strategy. Additionally, we’ll explore some of the common challenges organizations face with data and offer a few tips to help you understand the significance of proper data collection and compliance in AI and effective data management.
What is Data Quality? Why is it Important For AI Readiness?
Data quality is a set of frameworks, metrics, or processes that measure how closely a dataset meets the different data quality metrics, such as accuracy, completeness, validity, consistency, uniqueness, timeliness, and suitability for use. When we discuss data quality for AI, we are talking about the accuracy, completeness, consistency, and reliability of data used in AI models and systems.
As AI systems rely heavily on vast amounts of data, ensuring high data integrity and data governance services is crucial to building trustworthy and efficient enterprise AI-driven solutions. High-quality data directly impacts their ability to learn patterns, make predictions, and generate insights. So, poor data quality, such as incorrect labels, missing values, biases, or inconsistencies, can lead to flawed model outputs, skewed decision-making, and unintended consequences resulting in both financial and reputational damages.
Data Quality Metrics: How to Measure the Accuracy of Your Data
Specific parameters can help your business ensure the data you’re collecting, analyzing, or translating for AI models is of high quality, accurate, and valuable for a given purpose. Although these data quality metrics can differ based on the source of data input, generally, these are:

- Completeness: It checks the amount of data that is whole and intact. Your data must ensure that there are no empty or incomplete fields, as irrelevant values may generate biased or misleading analysis.
- Uniqueness: It tracks the quality of data in the sense of whether there’s data duplication or not. Every input has a different and unique value (in most cases); if it’s not, you will get data with similar results, wasting time and effort.
- Validity: This metric measures how well the data conforms to syntax, such as a format, type, or range for any business rules. It also reduces the risk of data-entry errors and invalid outputs.
- Timeliness: It refers to the readiness of the data within an expected time frame. Out-of-date information can lose its reliability, and in addition, if the data is old, it renders it useless in many ways.
- Accuracy: It ensures the correctness of the data values based on the pre-set “source of truth.” It’s important to have primary data sources instead of multiple sources. Inaccurate data is useless, and it also leads to poor decisions and wasted time and effort.
- Consistency: This metric assesses data records sourced from two different datasets. Doing so helps maintain consistent data trends and behavior, which leads to better and more useful actionable insights from the analyses.
- Relevance: It ensures that the data asset meets whatever business need has been decided. However, it’s challenging to evaluate as datasets keep evolving. But if done correctly and in a timely manner, you’ll be able to assess how informative and valuable the data is for a given purpose.
What Differentiates Data Integrity from Data Quality?
Even though Data quality and integrity are interrelated, data quality is a broader category of criteria that businesses utilize to assess data for accuracy, completeness, validity, consistency, uniqueness, timeliness, and fitness for purpose.
Whereas data integrity primarily emphasizes a specific set of attributes like accuracy, consistency, and completeness. Additionally, it is more concerned with keeping data secure while incorporating robust measures to protect against corruption caused by malicious entities.
Importance of Data Quality in AI for Businesses: 5 Benefits to Know
Businesses need effective data management to support their data analytics initiatives and deliver more intelligent decision-making. Poor or mismanagement of data quality could lead to ethical concerns, business losses, and more. So, let’s understand how high data quality in AI benefits you:

- Improved Accuracy: AI models rely on data to make predictions and decisions. High-quality data enhances the precision of these outputs, reducing errors and improving business outcomes. This leads to more confident and data-driven decision-making for businesses.
- Enhanced Efficiency: Clean and well-structured data allows your AI systems to process information faster and more effectively. With efficient data usage, you can minimize processing time, achieve smoother AI performance, and improve overall workflow competency.
- Better Customer Insights & Personalization: AI-driven analytics powered by quality data enable businesses to understand customer behavior more deeply, leading to personalized experiences and improved customer satisfaction.
- Lowering Business Costs: High-quality data minimizes the need for extensive data cleaning and error correction, reducing operational costs and improving overall efficiency. When your systems generate less error-prone results, it also prevents potential financial losses from incorrect AI-driven decisions.
- Reduced Risk of Bias: Poor data quality can introduce biases into AI models, leading to unfair or inaccurate results. With the high data quality, you mitigate this risk and support the development of ethical AI models, which produce balanced and unbiased AI outputs, enhancing trust and credibility among customers and stakeholders.
Redefining data efficiency with precision engineering and get high-performance analytics for seamless processing & insight generation!
Common Data Quality Challenges in AI: A Brief Look
Understanding potential problems is an essential early step in an AI project. Explore nine of the most frequently encountered data quality issues, such as biased or inconsistent data, sparsity and data silos.
- Incomplete & Inaccurate Data: AI models rely on having all the required data ready and correct. If the datasets are labeled badly or lack information, it can lead to significant errors in outputs.
- Too much data: An excessive amount of data can introduce noise, which results in AI models missing the main patterns and making it harder to distinguish significant trends from irrelevant details.
- Too little data: When there are few datasets to work on, models can use the data in a way that limits their performance with new data, leading to inaccurate results when applied to real-world scenarios.
- Biased data: If the way the data is selected, collected, or even labelled is not correct or flawed, it can adversely affect model behavior. Models may reinforce existing biases and amplify discrimination, prejudice, and other discriminatory outcomes.
- Data silos: It occurs when different departments or organizations who are working on the data is not easily or fully accessible by other groups in the same organization. This renders AI’s ability to learn from diverse datasets, reducing its effectiveness.
- Inconsistent data: When datasets consist of contradictory values or duplicate records, AI models may struggle to extract meaningful insights. Later, this makes it difficult for them to identify trends or patterns in the data correctly.
7 Strategies on How to Ensure High Data Quality in AI Projects
The significance of data quality for the success of your AI initiatives cannot be overstated. After all, poor data quality leads to biased models, inaccurate predictions, and even costly failures. To avoid these issues, we’re sharing 7 essential steps to maintain high data quality throughout the AI lifecycle. These are:
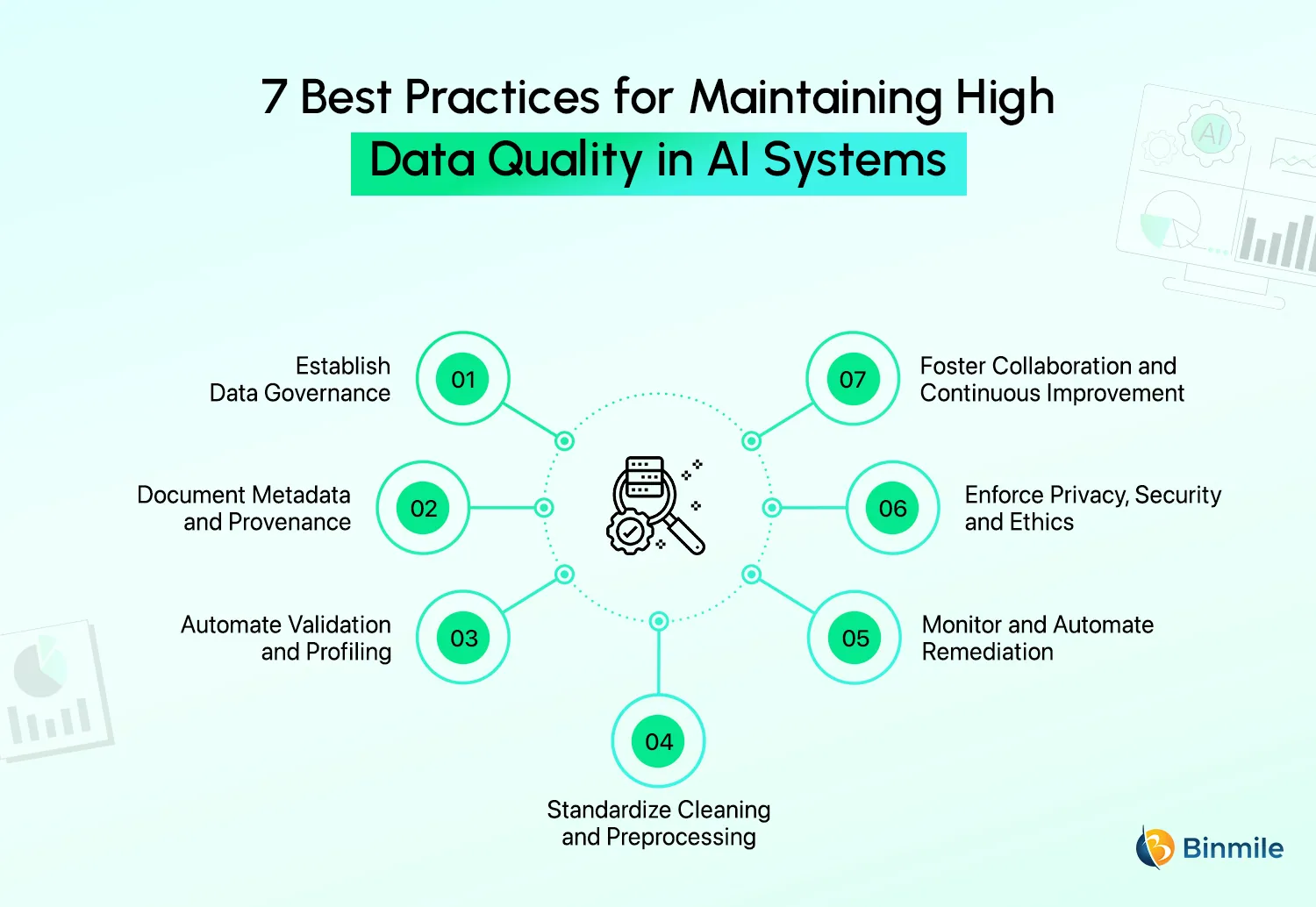
1. Establish Data Governance
Effective data governance sets the tone for maintaining sustained data quality. It requires clearly defined roles, responsibilities, policies, and standards. Without explicit ownership and accountability, data quality efforts risk becoming fragmented and unsustainable. Early formation of cross-functional teams, comprising data engineering, data science, business stakeholders, and domain experts, ensures diverse perspectives and shared responsibility.
- Develop comprehensive governance policies with well-defined roles and standards.
- Establish dedicated cross-functional teams focused on data quality
- Schedule regular review meetings to evaluate quality metrics and prioritize improvements
- Create incident response procedures to address quality issues promptly
- Provide training on data integrity and its business impact
2. Document Metadata and Provenance
Understanding the context and lineage of data is vital for accurate interpretation and consistent quality throughout its lifecycle. Maintaining detailed documentation and metadata enhances communication, troubleshooting, and traceability. This information should be regularly updated as projects evolve.
- Create detailed data dictionaries describing field definitions, constraints, and quality requirements.
- Track data provenance and maintain version histories of schemas and transformation logic
- Automated tools are used to capture and manage metadata, including technical properties and relationships.
- Maintain searchable data catalogs highlighting dataset availability and quality status.
- Document known data issues, their impacts, and mitigation steps
3. Automate Validation and Profiling
Detecting anomalies, missing values, duplicates, and inconsistencies early prevents poor-quality data from affecting downstream processes. Automating validation and profiling improves efficiency and helps maintain rigorous data standards:
- Automate data profiling to analyze distributions, data types, and value ranges
- Define and enforce validation rules to identify missing, outlier, or improperly formatted data.
- Perform schema validation to ensure structural consistency across sources and over time.
- Generate data quality scorecards to quantify completeness and accuracy.
- Implement real-time alerts for threshold breaches during data ingestion.
4. Standardize Cleaning and Preprocessing
Raw data rarely comes ready for modeling. Standardizing cleaning and preprocessing procedures reduces errors, improves maintainability, and supports reproducibility across environments:
- Establish repeatable methods for handling missing data, outliers, and anomalies
- Develop reusable transformation libraries for normalization, encoding, and feature engineering.
- Clearly define criteria for excluding, imputing, or flagging irregular data points.
- Use version control for preprocessing logic to ensure transparency and enable rollback.
- Document all transformation steps and their rationale to improve interpretability.
5. Monitor and Automate Remediation
Data quality may degrade post-deployment due to changes in source systems or evolving business processes. Continuous monitoring, coupled with intelligent alerting and automated remediation, enables prompt issue detection and resolution, preserving model performance and stakeholder trust.
- Implement dashboards to track key metrics such as completeness, distribution shifts, and anomalies.
- Use intelligent alerting systems to distinguish between normal variance and real issues.
- Monitor data drift by comparing incoming data against historical baselines.
- Define escalation procedures for the efficient resolution of critical problems.
- Automate the correction or flagging of common data quality issues where feasible.
6. Enforce Privacy, Security, and Ethics
Data quality encompasses accuracy and completeness, as well as compliance with privacy regulations, ethical standards, and security protections. Safeguarding these dimensions protects data integrity, reduces legal risk, and fosters trust:
- Establish and enforce data privacy policies aligned with regulations such as GDPR and CCPA
- Implement role-based access controls and encryption to protect sensitive information
- Regularly audit data access and usage logs to detect unauthorized activity
- Define ethical guidelines to prevent bias, discrimination, and unfair practices in AI models
- Train teams on data privacy, security best practices, and responsible AI principles
7. Foster Collaboration and Continuous Improvement
Data quality is an ongoing process that requires sustained effort and alignment across teams. Continuous collaboration and feedback ensure that data quality practices evolve with business needs and technology changes:
- Keep cross-functional teams engaged through periodic reviews and joint initiatives
- Facilitate transparent sharing of data quality insights and challenges via collaborative platforms
- Incorporate feedback from business stakeholders and data consumers to refine processes
- Adapt governance policies and quality controls to changing requirements.
- Promote ongoing education on data quality impacts and recognize successes to build organizational maturity.
Precision AI, powered by reliable data, crafted to tackle your industry's toughest challenges with confidence, impact, and accuracy.
Closing Statement on the Importance of Data Quality in AI
Data is the driving factor behind many mission-critical AI-driven business decisions. If you fail to ensure high data quality in AI models or GenAI solutions, even the best algorithms can lead you astray. To make AI more reliable, scalable, and worth the investment, you call for clear ownership, long-term planning, and alignment across teams. If your organization needs to move fast without cutting corners, experienced data consultants can offer the structure and methodologies required to build strong foundations.
With the right approach, data quality won’t slow you down. It’ll keep your AI journey on track. For companies looking to move quickly without compromising on quality, working with data engineering services companies can help bridge the gap. These data specialists offer the expertise and frameworks needed to embed data quality into the core of AI projects, reducing friction, accelerating deployment, and ultimately enabling systems that are not only high-performing but also trustworthy and scalable.
Need help building that foundation? Contact us to explore how our data experts can support your AI strategy.









