
Businesses strive to deliver seamless digital experiences and drive innovation. But that’s not possible if their IT infrastructures and operations keep hitting downtime and are difficult to manage. There can be multiple reasons for it, both external or internal in site reliability engineering but if your organization cannot quantify the business impact of technology, you’re missing out on a lot. Moreover, with the increasing levels of complexity of IT assets, investing in business-critical monitoring tools with a lack of visibility and data silos between technology and business teams can prove to be quite ineffective. That’s when businesses develop an observability strategy. As it offers them a unified, real-time visibility into availability and performance up and down the IT stack.
Observability is the key in site reliability engineering that enables businesses to monitor and optimize the availability and performance of their IT stack across a more dynamic and fragmented technology landscape. Therefore, it’s imperative for businesses to create the best observability strategy that gets you visibility into how your apps, networks, or systems impact your business. In this blog, we’ll discuss this and also explore a brief insight into observability, its benefits, and its major components. Thus, helping you make data-driven decisions and achieve significant financial gains with your IT asset management and investment.
Step-by-Step Guide to Develop An Observability Strategy for Efficient SRE
For many organizations having proper visibility over their infrastructure and utilizing it in site reliability engineering is a challenging task, that’s where observability comes into the picture. As a process, observability utilizes a combination of tech tools, best practices, and a proactive mindset. Let’s discuss some tips to develop an observability strategy that not only helps businesses react swiftly to challenges but also captures growing opportunities in an ever-changing technological landscape.
Here are 5 best practices to elevate your observability plan.

1. Establish Key Metrics
To build an observability strategy for site reliability engineering and your tech stack, you need to start by defining key metrics. These are the specific performance indicators that matter most for your system and business objectives. Consider things like response times, error rates, system resource utilization, and user interactions. Metrics help you navigate your observability efforts, giving you a clear picture of what aspects of your system require constant monitoring, analysis, and mitigation.
The challenge in defining metrics is to find the right balance between observability and monitoring. Too many metrics can overwhelm you with information, while too few may make you miss important aspects. Aim for a set of metrics that match your business goals and offer actionable insights.
2. Select Appropriate Tools
There are many observability and monitoring tools in the market that have their own features and capabilities. Consider what are the requirements of your system architecture, and other factors such as scalability of the tools, cost, and the level of in-depth analysis they can provide. Factors like logging, monitoring, tracing, or alerting, should be prioritized and whatever tool you choose, must fit your organization’s needs. The technology landscape is dynamic, and new observability tools appear regularly.
Don’t be afraid to explore and adopt new tools that might offer improved features or better integration with your existing infrastructure and simplify the site reliability engineering process. Flexibility and adaptability are key in the ever-changing field of observability.
3. Build a Culture of Observability
Observability is more than a technical solution; it’s a cultural change in an organization. To create a culture of observability, you need to break down the barriers between developers and operators. Promote cooperation and joint accountability for system observability. Make sure that everyone on the team knows why observability is vital for system reliability and has the skills to participate effectively.
The successful implementation of your observability strategy depends a lot on your team’s approach to it. So, rather than making it a team or an individual’s task to adopt the strategy, foster a culture where everyone can contribute to the system’s observability.
4. Set Up Intelligent Alerting Mechanisms
Establish clear and actionable notifications based on the important metrics you identified earlier. These alerts should inform your team quickly when predefined limits are exceeded. Aim for a balance between reducing false alarms, which can cause alert fatigue, and making sure that serious problems are not missed. Setting up good alerts requires a good understanding of your system’s normal behavior. Utilize the power of artificial intelligence for IT operations’ repetitive tasks, saving time and effort.
Don’t set alerts randomly; instead, base them on a careful analysis of historical data and a deep knowledge of your application’s features.
5. Iterate and Improve
Just developing an observability strategy is not enough or neither treat it like a fixed goal. It’s a dynamic process that needs constant improvement. We recommend you review and update your strategy regularly based on how your system or requirements go through changes, the latest best practices, and the insights gained from security or performance-related issues. Seek feedback from your team members, and be flexible to changes that better suit the changing needs of your organization.
Adopt a mindset of continuous improvement. The organizations that excel in observability are those that view it as an ongoing journey rather than a one-off project. Revisit and revise your strategy frequently to keep up with emerging challenges.
Looking for ways to make your applications observable and digital solutions to make your systems reliable and resilient? We’ve got you. Get in touch with us today!
The Role of Observability in Building Resilient Site Reliability Engineering
Observability is a crucial pillar of site reliability engineering (SRE). It enables businesses to detect and diagnose issues as they happen and before they cause customer-impacting outages or performance degradation. Today’s modern cloud environments are dynamic and constantly changing in scale and complexity. Therefore, software testing teams or IT teams neither know about nor can monitor most problems, not in real-time with traditional monitoring tools.
What differentiates observability and monitoring is that while monitoring alerts the team to a potential issue, observability helps the team detect and solve the root cause of the issue. So, when you develop an observability strategy, it enables you to continuously and automatically understand new types of problems as they arise.
Top 3 Components of an Effective Observability Strategy
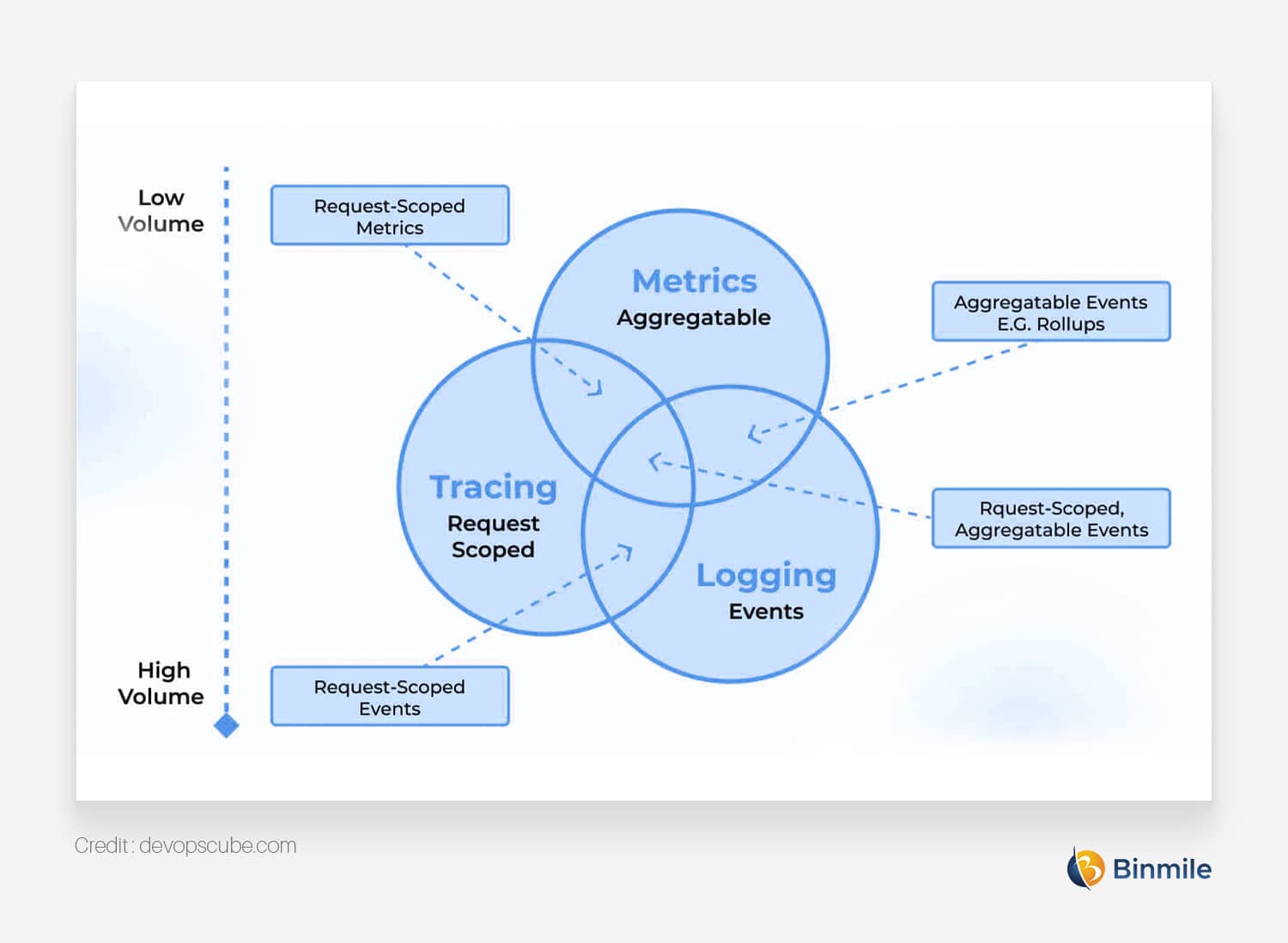
- Monitoring: To get a real-time update and quick resolution regarding any issues in the system or network, you need to conduct regular monitoring of metrics such as response times, error rates, and resource utilization that you’ve predefined when you develop an observability strategy.
- Logging: These logs are the backbone of your observability strategy, so make them detailed and well-defined. With their help, you get a chronological record of events, thus, letting you identify the sequences of events and correct those anomalies.
- Tracing: As the name suggests, tracing lets you follow the flow of workflow of a single request through a distributed system, end-to-end via a system. This makes debugging and understanding distributed systems, microservices architecture, and containers much simpler and easier.
Also Read: Observability in DevOps
Benefits of Observability Strategy: Top 4 to Remember
- Get a Holistic Enterprise View: With an observability strategy in place, you get a panoramic view of your data, application, and network systems. Therefore, when you have easy access and real-time visibility to your tech stack, you can streamline your IT operations, and mitigate risks like performance engineering-related issues.
- Early Detection of Issues: With proactive and effective observability, one can identify and address potential problems before they escalate and can cause severe damages both financial and reputational.
- Optimizing Performance: Observability is not just about addressing problems during site reliability engineering practices; it’s also about optimizing performance. By analyzing system metrics, you can identify bottlenecks and areas for improvement, leading to a more efficient and responsive system.
- Enhanced End-user Experience: An effective observability strategy helps you understand a system’s internal state solely through that system’s outputs. When your application, systems, or software are up and running flawlessly, this not only helps you in better decision-making but also provides a seamless and smooth user experience to your users- whether stakeholders or customers.
Looking to strengthen your IT stack? Discover custom software solutions for resilient systems and optimized site reliability engineering!
Wrapping Up
Building a highly available, resilient system and optimized site reliability engineering process, needs both observability and monitoring. This along with a well-thought-through and executed strategy for automated monitoring, alerting, and recovery. An efficient observability strategy is what makes the difference between a minor issue that is quickly resolved, and a major issue that causes widespread customer impact. For instance, without steps to develop an observability strategy, much can go wrong with your business— delaying troubleshooting, driving up costs, wasting engineering resources, and posing security risks.
Hopefully, this blog has provided you with an understanding of how observability helps you get complete visibility of your systems, apps, software, or infrastructure to help you mitigate performance or security risks. Thus, empowering you to make informed decisions and shape your infrastructure, architecture, application, and storage systems to be more robust, reliable, and resilient. The observability strategy we shared will help you overcome these risks, and seeking a software development services company can make them easier to implement.
Frequently Asked Questions
An Observability Roadmap is a strategic plan that outlines the steps and initiatives an organization will undertake to improve its observability capabilities over time. It defines objectives, milestones, and key activities aimed at enhancing the organization’s ability to understand, troubleshoot, and optimize complex systems.
Observability refers to the ability to understand and measure what’s happening inside a system based on its external outputs.
Implementing Observability involves using tools and practices such as logging, monitoring, distributed tracing, and metrics collection to gain insights into the behavior and performance of your system.
Observability is crucial because it allows you to quickly detect and diagnose issues, improve system performance, and ensure the reliability and availability of your applications and infrastructure.









